





ログインしなきゃ現れない情報を取得したい場合、seleniumを用いてページ遷移・ログインし、遷移先のデータを取得している方もいると思います。
今回は、requestsモジュールを用いてログインし、同一セッション内でデータを取得する方法を備忘録がてら書いていこうと思います!
ただし、おそらく動的なサイトに関しては従来通りseleniumでページ遷移する必要があるかもです、、、。
取得したい内容
今回取得したい内容はこんな感じです。
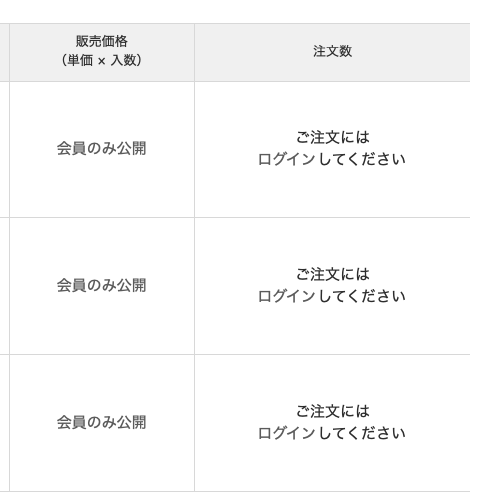
ある商品の販売価格や注文数などを取得したいのですが、ログインしないとこれらの情報は現れません。
ログインした後の、同様のページを見てみましょう。
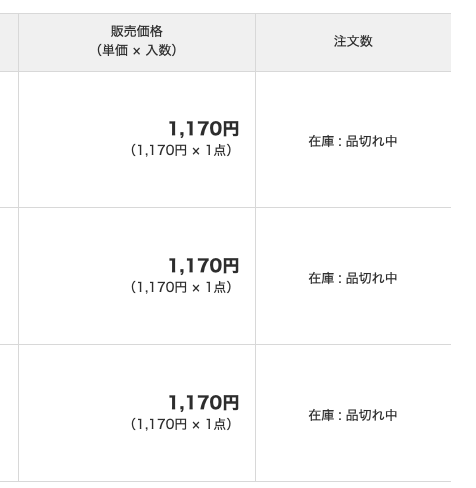
このように、ログインした後なら値段や在庫などが取得できるようになっています。
試しにこの情報をrequestsで取得してみましょう。(ログインなし)
import requests
from bs4 import BeautifulSoup
url = '[対象url]' # 対象商品のurl
html = requests.get(url).content
soup = BeautifulSoup(html, 'html.parser')
txt = soup_find_all('[欲しい要素]')
print(txt)こちらの出力がこちらです。

南無。
もちろんログインしていませんので、情報を取得することができません。
ログインするには何が必要?
まず対象のサイトのログイン画面はこんな感じです。(一部を切り取っています)
めちゃくちゃよくあるログイン画面。
seleniumの場合、「メールアドレス」と「パスワード」の要素を取得して、文字を入力してログインボタンを押す、、、といった流れかと思います。
しかし、今回はrequestsを用いてログインしていきたいのですが、その際に集めなければならない情報があります。
突然ですがその前に、まずはログインするまでの個人的な抽象的イメージを書いていきます。
例えばある遊園地に入りたい時、その門の前には入る人を選抜する警官(声低め、髭濃いめ)が立っているとします。
この人は、入る人がちゃんとチケットや身分証を持っているか確認し、その身分証の内容を事務に伝え、ちゃんと登録されていることが確認できて初めて入園することができます。
ここで言う「チケット」や「身分証」が、ページでログインする際の「ID」や「パスワード」に相当します。めちゃくちゃ強引ですがご容赦ください。
具体的に、何が必要か見ていきましょう!
今回のログインサイトの<form>タグの中の<input>タグを抜粋して記載します。
<form method="POST" action="https://[POST先のURL(サイト毎に異なる)]" id="login-form">
<input name="_token" type="hidden" value="uqDxmDajGelD07wD6ewFRb265nul1F74S8FkE9Bw">
<section class="input">
<input class="textfield width-l" name="loginEmail" type="text">
<input class="textfield width-l" name="loginPassword" type="password" value="">
<input class="__check" name="remember" type="checkbox" value="1"> ログイン状態を保存する</label>
<input name="login" class="__button c-button-submit" type="submit" value="ログイン">
</section>
</form><form>タグの中に5つの<input>タグがあります。全部の name=””の部分をぶち抜いてみましょう。
✔︎ _token
✔︎ loginEmail
✔︎ loginPassword
✔︎ remember
✔︎ login
また、次のコードに注目。
<form method="POST" action="https://[POST先のURL(サイト毎に異なる)]" id="login-form">ここに、上記に記載した情報をPOSTするURLが記載されています。
したがって、ログインするまでのおおまかな流れとしては、
- 上記の5つの情報を集める。
- action=””に記載してあるURLにPOSTする。
となります!
ログインに必要な情報を集める
再度必要な情報を記載します。
✔︎ _token
✔︎ loginEmail
✔︎ loginPassword
✔︎ remember
✔︎ login
ログインに必要な情報を集める!なんて大それて書きましたが、_token以外は特に集める必要がないのがわかりますでしょうか?
loginEmail, loginPasswordは、サイトに登録する際に自分で決めたもので、rememver, login に関しては、同じタグのvalue=””の部分に記載されています。
<input class="__check" name="remember" type="checkbox" value="1"> ログイン状態を保存する</label>
<input name="login" class="__button c-button-submit" type="submit" value="ログイン">ここです。
それぞれ、”1″, “ログイン”です。
では _tokenはというと、この文字列はサイトにアクセスするたびに変化し、都度取得してあげる必要があります。忙しないやつなんです。
具体的に_tokenを取得するコードを見てみましょう!
url_login = '[ログイン画面のURL]'
html = requests.get(url_login).text
soup = BeautifulSoup(html, 'html.parser')
_token = soup.find(attrs={'name':'_token'}).get('value') # サイトによって内容は異なります。これでトークンを取得できます。
ログインしてみる
材料が揃ったのでいよいよログインしてみます!
import requests
from bs4 import BeautifulSoup
def login_by_requests():
# メールアドレスとパスワードの指定
USER = "[アカウント登録時に設定したID]"
PASS = "[アカウント登録時に設定したパスワード]"
# セッションを開始
url_login = "[ログイン画面のURL]"
session = requests.session() # セッションインスタンス作成
res = session.get(url_login)
# BeautifulSoupオブジェクト作成(token取得の為)
soup = BeautifulSoup(res.text, 'html.parser')
# tokenの取得
_token = soup.find(attrs={'name':'_token'}).get('value')
cookie = res.cookies # cookie も一緒にPOSTしなければならないので取得
# ログイン時にPOSTする情報
login_info = {
"loginEmail": USER,
"loginPassword": PASS,
"_token": _token,
"remember": "1",
"login": "ログイン"
}
# action
url_login = "[ログイン時にPOSTするURL]"
res = session.post(url_login, data=login_info, cookies=cookie)
print('status_code : '.format(res.status_code))
return session以上がログインするまでの一連の流れです。
‘status_code : 200’と出力されていれば成功です!
では早速、ログインした後の状態で先ほどの在庫情報を取得してみましょう!
session = login_by_requests() # 先ほどのログイン済みのsessionを取得
url = '[対象url]' # 対象商品のurl
html = session.get(url).content # ログイン済みのsessionを用いてページ内容を取得
soup = BeautifulSoup(html, 'html.parser')
txt = soup_find_all('[欲しい要素]')
print(txt)
session.close() # セッションの終了以下が出力結果です。

しっかりログイン後の情報が取得できました!
まとめ
少しでもrequestsを用いてログインする仕組みが理解できたら幸いです!
再度になりますが、この方法で取得できない情報も勿論あると思います。その場合はseleniumを用いるなど、臨機応変に使い分ける必要があります。
あくまでスクレイピングの一つの手法という認識で見ていただけたらと思います!
ご覧いただきありがとうございました!







コメント