





競艇や競馬の過去データで、「レースごとのタイムの平均」 といった集計値を新規カラムとして追加する、などという処理を簡単にしたいなあ、なんて色々調べてる際に、groupby().transform()というとても便利なメソッドを見つけたので、備忘録がてら書き残します。
公式ドキュメントはこちら。
あわせて読みたい
目次
結論
# サンプルデータ用意
data = {
'class': ['A', 'A', 'B', 'C', 'B', 'A', 'C', 'C', 'C'],
'point': [80, 68, 50, 9, 54, 93, 3, 18, 33]
}
df = pd.DataFrame(data)
# グループごとの集計値カラム追加(ここでは平均値)
df['point_mean'] = grouped.transform('mean')['point']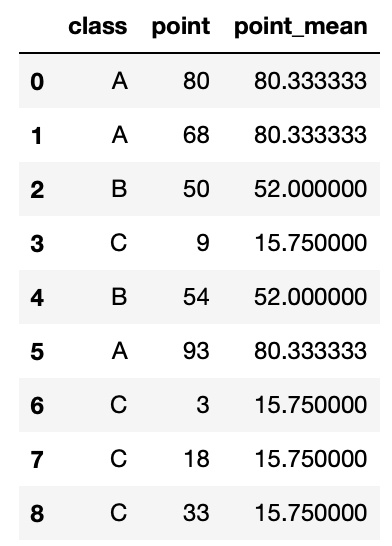
噛み砕いて
サンプルデータ
まずサンプルとなるデータを作成します。
分かりやすいように、あるテストの点数と、その人が所属するクラスが入力されたデータを想定します。
data = {
'class': ['A', 'A', 'B', 'C', 'B', 'A', 'C', 'C', 'C'],
'point': [80, 68, 50, 9, 54, 93, 3, 18, 33]
}
df = pd.DataFrame(data)
ただのgroupby()
グルーピングし、主計値(平均)を計算してみます。
grouped = df.groupby('class')
grouped.mean()
各グループの平均値を算出できました。グループAは優秀ですね。
transform()メソッド
このままですと、グループの数しか行が作成されません。
しかし、transform()メソッドを使用することで、もとのデータの行数を維持したまま集計値を算出してくれます。
grouped.transform('mean')
こうすると分かりやすいでしょうか。
df['point_mean'] = grouped.transform('mean')['point']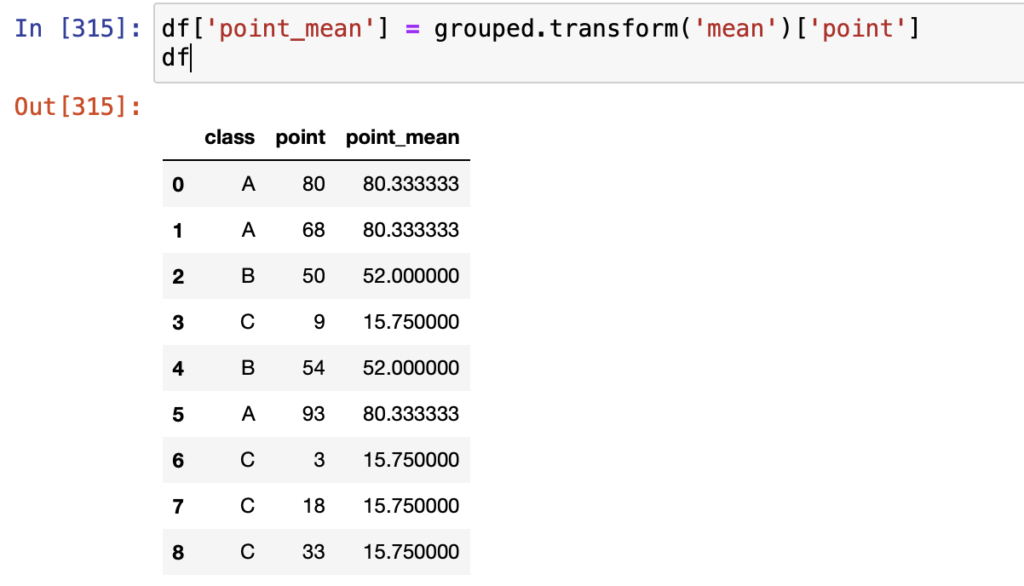
1行でグループごとの集計値を追加することができました。






08-300x158.png)
07-300x158.png)
コメント