






本記事では、「pythonを用いてスクレイピングを行ってみたい!」といった方向けに、基本的な知識や注意事項、実際にスクレイピングのプログラムを作成するまでご紹介していきます。
・そもそもスクレイピングって何?
・実際にpythonを用いてスクレイピングをしてみたい!
・注意点とかある?
※htmlやcssに対する知識をある程度要します。htmlとは?cssとは?については言及しておりませんのでご了承ください。
スクレイピングってなに??
そもそもスクレイピングとはなんでしょうか?
簡単に言うと、Web上の情報をプログラムを用いて収集する作業です。
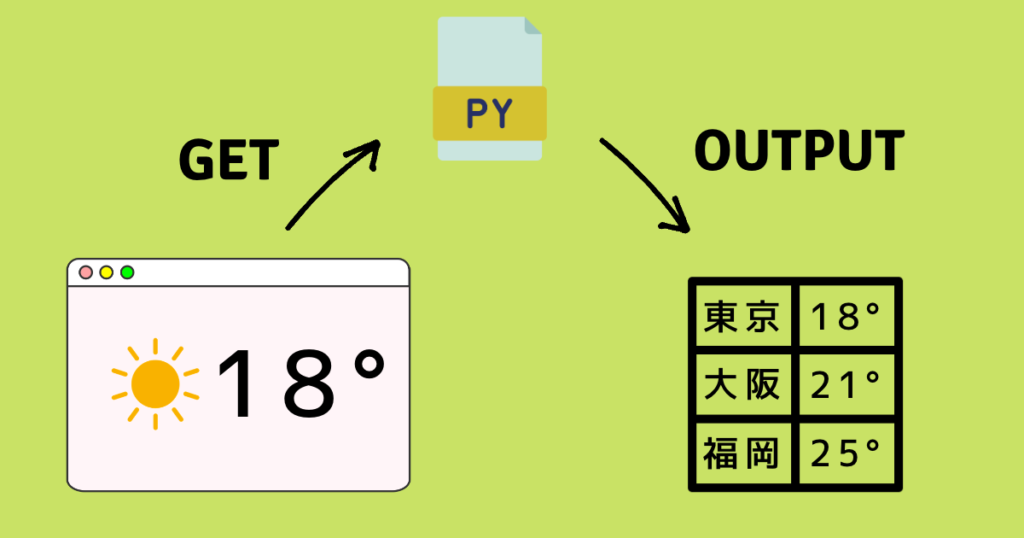
例えば、このように全国の気温をWebサイト上から取得し、そのデータをcsvとして出力したり。
スクレイピングの目的は多岐に渡りますが、基本的にWeb上のデータなら取得することができます。
ビジネスシーンでいうと、市場調査・競合調査・相場調査などに活用できるかと思います。
また一度プログラムを作成してしまえば、そのプログラムを定期実行させることでコンスタントに情報を収集することだってできちゃいます!(メンテナンスは必要ですが、、、)
定期的に取得した情報をbotにツイートさせちゃうことだってできます。
好き勝手スクレイピングってしていいの?
結論:よくありません!!!!
何事もルールと節度を守らなければなりません。
具体的にどんなことに注意しなければならないのか紹介していきます!
スクレイピングを禁止しているサイトがある
そもそもスクレイピングの禁止をしているサイトがあります。
例えば皆さん大好きAmazonさんです。こちらの利用規約をご覧ください。
本規約およびサービス規約の遵守を条件とし、アマゾンまたはコンテンツ提供者は、アマゾンサービスを限定的、非独占的、非商業的および個人的に利用する権利をお客様に許諾します(譲渡およびサブライセンス不可)。この利用許可には、アマゾンサービスまたはそのコンテンツの転売および商業目的での利用、製品リスト、解説、価格などの収集と利用、アマゾンサービスまたはそのコンテンツの二次的利用、第三者のために行うアカウント情報のダウンロードとコピーやその他の利用、データマイニング、ロボットなどのデータ収集・抽出ツールの使用は、一切含まれません。(一部抜粋)
「利用許可およびサイトへのアクセス」より
技術的にはスクレイピングをして情報を収集することは可能ですが、きちんと利用規約に則った行動をするよう注意しましょう!
アクセス頻度に注意する
2つ目に注意すべき点はアクセス頻度です。
そもそも、Webサイトがあなたの画面に表示されるまでの流れを大分簡潔に説明しますと、
- サーバーと呼ばれるコンテンツを保存している場所に、データを要求する。
- サーバーから受け取ったデータを基にブラウザがページを表示させる。
といった流れでございます。
重要なのは、Web上の情報を表示・取得するためにはサーバーにアクセスする必要があるということです。
スクレイピングも例外ではありません。
自分の携帯やPCでアクセスする分には物理的に限度がありますが、プログラムを使用した場合は短時間で気持ち悪いほどのアクセスを行うことができます。
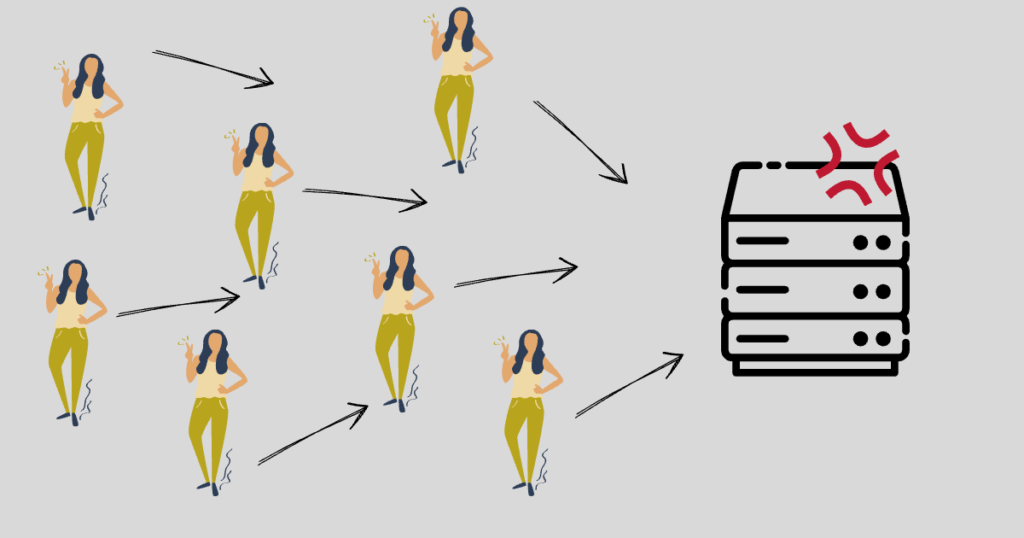
結果サーバーに負荷がかかってしまいます!
もし理不尽なアクセスを行った場合、サイト側がそのアクセスを「攻撃」とみなし、BANされてしまう場合もあります。
 新米エンジニア
新米エンジニアどのくらい間隔を開ければいいんだ???
最低でも0.5~1.0秒は間隔をあけるようにしましょう!
ただ実際はアクセス間隔のみならず「どの程度の時間アクセスを行うか」も考慮しなければなりません。
身も蓋もない話ですが、どのようなアクセスを行ったらBANされるかはサイトによってピンキリであり、「これが正解!」というのはありません。
業務としてのスクレイピングプログラムを作成している際は最低でも3秒は間隔をあけておりました。
実際にスクレイピングしてみる
スクレイピングをするにあたっての大まかな流れは次の通りです。
- 材料を取得
- 取得した材料をpythonで扱えるように解析する
- 欲しい情報を抽出する
ぜーーんぶ抽象的ですね。
まずここで言う材料とは、サーバーから取得したそのページのhtml要素です。
ただし取得したhtml要素は、そのままではpythonで扱うことができないので、解析してあげます。
最後に、解析したデータから欲しい情報を抽出します。
ざっくりですがこのように段階分けすることができます。
材料を取得する
まずはサーバーからhtml情報を取得しましょう!
今回は Yahoo!天気 を例として進めていきたいと思います。
pythonでHTTP通信を行うことができる requests というモジュールを使用します。
import requests続いて、requestsのget()メソッドを使用してhtmlを取得します。
# 取得したいサイトのURL
url = 'https://weather.yahoo.co.jp/weather/'
# get()メソッドを使用してhtml要素を取得
html = requests.get(url).content解析する
続いて先ほど取得した要素を解析します。
解析するために、pythonの BeautifulSoup というライブラリを使用します。
# 'html.parser'モードで解析する
soup = BeautifulSoup(html, 'html.parser')この1行で解析を行うことができます。
タイプを確認してみると、ちゃんと bs4.BeautifulSoup オブジェクトになっています。
# 型タイプを確認
print(type(soup)) # bs4.BeautifulSoup欲しい情報を抽出する
ここまでで下ごしらえが終わったとこで、いよいよ欲しい情報を抽出していきます。
まずはシンプルな例で抽出をおこなってみます。
<div>
<h2>お天気情報</h2>
<ul>
<li>最高気温は18°です。</li>
</ul>
<div>このようなページデータ(htmlデータ)から、「最高気温の情報」を抽出したいとしましょう。4行目の情報ですね。
ここで重要なのが、数ある手がかりの中から欲しい情報にマッチする条件を自分で決めることです。
手がかりとしては、、、
- id属性
- class属性
- タグ名
- その他属性値
などが挙げられます。
では最高気温が記載されている部分の、抽出できるような条件を探してみましょう。
そうです、唯一 <li> タグが使用されています。なので <li> タグを条件に情報の抽出を行なってみます。
# <li>タグのみ抽出
tag_li = soup.find('li')find()メソッドを用いることで、タグによる抽出を行うことができます。
実際に抽出した中身を見てみると、このようになります。(※jupyter notebookを使用しております。)

ちゃんと狙った情報が抽出できているのが確認できます。
ただし余計なタグの情報が含まれてしまっているので、get_text()メソッドを使用して中身のみ抽出しましょう。

このように中身のみを文字列として取得することができます。
もし数字の「18」のみが欲しい場合は、置換や正規表現による抽出などを適宜行いましょう!(本記事の主題とは逸れますので割愛いたします。)
- タグ名で欲しい情報を抽出
- get_text()メソッドで中身のみを取り出す
さあ、これで簡単な抽出はできるようになったかと思います!
では次のような場合はどう抽出すればよいでしょうか??
<div>
<h2>お天気情報</h2>
<ul>
<li>最高気温は18°です。</li>
<li>最低気温は12°です。</li>
</ul>
<div><li>タグが2つになりました。そして「最高気温」「最低気温」2つの情報が欲しいとしましょう。
まあ気にせず先ほどと同様にタグ名による抽出を行なってみましょう!
# <li>タグによる抽出
tag_li = soup.find('li')中身を確認してみます。

困ったことに、最高気温の情報しか取得できていません。
こんな時は find_all() メソッドを使用します
このメソッドを使用することで、条件に当てはまるすべての情報をリスト形式で取得することができます。
# <li>タグによるすべての情報を抽出
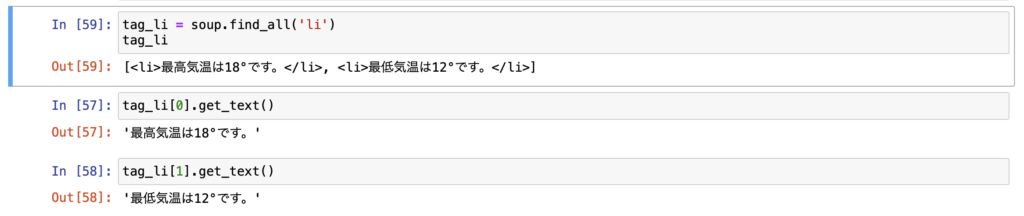
tag_li = soup.find_all('li')
このようにリスト形式で取得することができます!
find_all()メソッドにより、条件に合ったすべての情報をリスト形式で取得できる。
※find()メソッドは、条件に当てはまる最初の要素のみ取得できる。
返ってきたリストを使用して、最高気温・最低気温を抽出することができます。
ただこの方法、なんか面倒というか冗長的、、、と思いませんか?
サイト構造によりけりですが、もっとスマートに欲しい情報のみ抽出できる場合があります。
それはどのような場合かというと、タグにidやclass名が付与されている場合です。
<div>
<h2>お天気情報</h2>
<ul>
<li class="temp-high">最高気温は18°です。</li>
<li class="temp-low">最低気温は12°です。</li>
</ul>
<div>こんな感じです。
このようにclass名などといった属性値が定義されている場合、それらも抽出条件に使用することができます。
# タグ名、クラス属性を用いた抽出
temp_high = soup.find('li', {'class': 'temp-high'})
temp_low = soup.find('li', {'class': 'temp-low'})
# このような記述方法もあります
temp_high = soup.find('li', class_='temp-high')
temp_low = soup.find('li', class_='temp-low')
find()メソッドの第2引数に属性の条件を辞書型として渡すことで、より条件を厳しくすることができます。
もちろん複数の属性を指定することもできます。
<div>
<h2>お天気情報</h2>
<ul>
<li class="temp" id="temp-high">最高気温は18°です。</li>
<li class="temp" id="temp-low">最低気温は12°です。</li>
<li>過ごしやすい気候でしょう。</li>
</ul>
<div># class名とid名を指定
temp_high = soup.find('li', {'class': 'temp', 'id': 'temp-high'})実際にスクレイピングをする際、欲しい情報にidが付与されている場合はラッキーです。
なぜなら、id属性は原則1ページに対して1つしか付与してはいけないからです。なのでその条件に対して複数要素がヒットしてしまうことは無く、簡単に欲しい情報を抽出することができます。
ただ今まで担当してきたサイトにて、同じidが複数付与されているやんちゃなページも実際にありましたので、念の為find_all()を使用して複数ヒットしてしまっていないか確認することをおすすめします、、。
タグ名、class名、id属性などを活用して欲しい情報を抽出する。
色々なテクニックはありますが、基本的な抽出方法は以上です!
では実際にYahoo!天気のサイトから情報を抽出してみます。
そのために、まず該当ページのhtmlを覗いてみましょう。
htmlの表示方法は、該当ページの任意の場所で右クリックをし、「検証」を選択することで表示させることができます。(chromeの場合)
chrome以外の場合は、「[ブラウザ名] 開発者ページ 表示]などと検索すると表示方法を解説した記事がヒットするかと思います。
実際に表示させるとこのような画面になります。
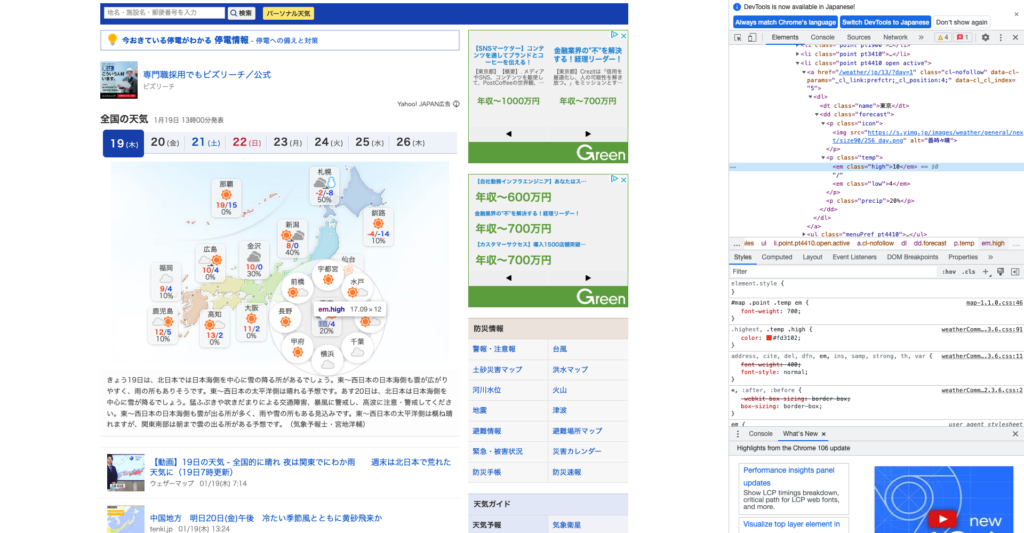
ページを構成しているhtml要素が表示されました!
右側の気温情報の部分を拡大してみます。
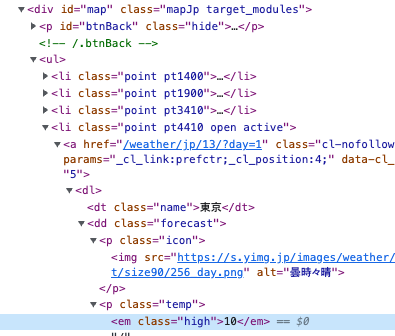
まずは近くの親要素にidが定義されているタグがあるかをチェックします。(絞り込みが容易になるため)
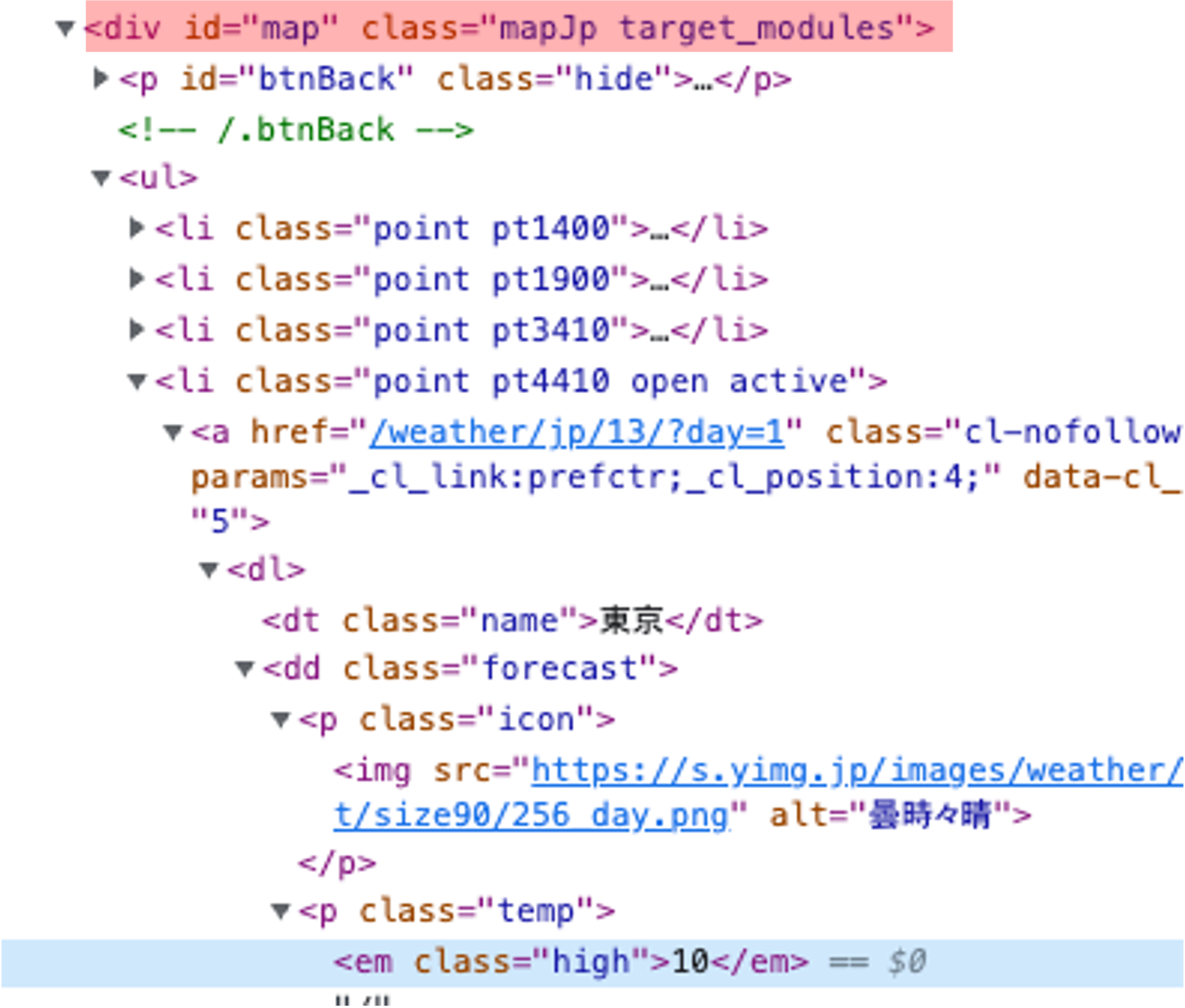
ありました!(赤塗りつぶし部分)
<div>タグに id=”map” が定義されております。
念の為、このページ内に複数同じidがないかどうか確認します。
# <div>タグ & id="map" の要素が何個あるか確認する
len(soup.find_all('div', {'id': 'map'})) # expected output: 1find_all()メソッドで帰ってきたリストの要素数が1でしたので、同じidが複数無いことを確認できました!
さらにページのhtml要素を確認してみると、<li class=”point [地域特有の番号?]”> というタグ内に、各地域の名称や気温などの情報が格納されていることがわかります。
なので各<li>タグ要素を取得してみましょう。
# 各地域の気温などが格納された<li>タグを取得する
li_point = soup.find('div', {'id': 'map'}).find('li', {'class': 'point'})
# 返ってきた要素数を確認する
len(li_point) # expected output: 13(地図上の地域の数と一致する)無事各地の情報が格納された<li>タグを取得できました。
ここで<li>タグ内を確認してみましょう。

地名、最高気温、最低気温にそれぞれクラス名が指定されておりますので、これを使用して抽出していきます。
# 情報抽出
for i in range(len(li_point)):
name = li_point[i].find('dt', {'class': 'name'}).get_text() # 地名
temp_high = li_point[i].find('em', {'class': 'high'}).get_text() # 最高気温
temp_low = li_point[i].find('em', {'class': 'low'}).get_text() # 最低気温
print('--------\n')
print(f'名称: {name}')
print(f'最高気温: {temp_high}')
print(f'最低気温: {temp_low}')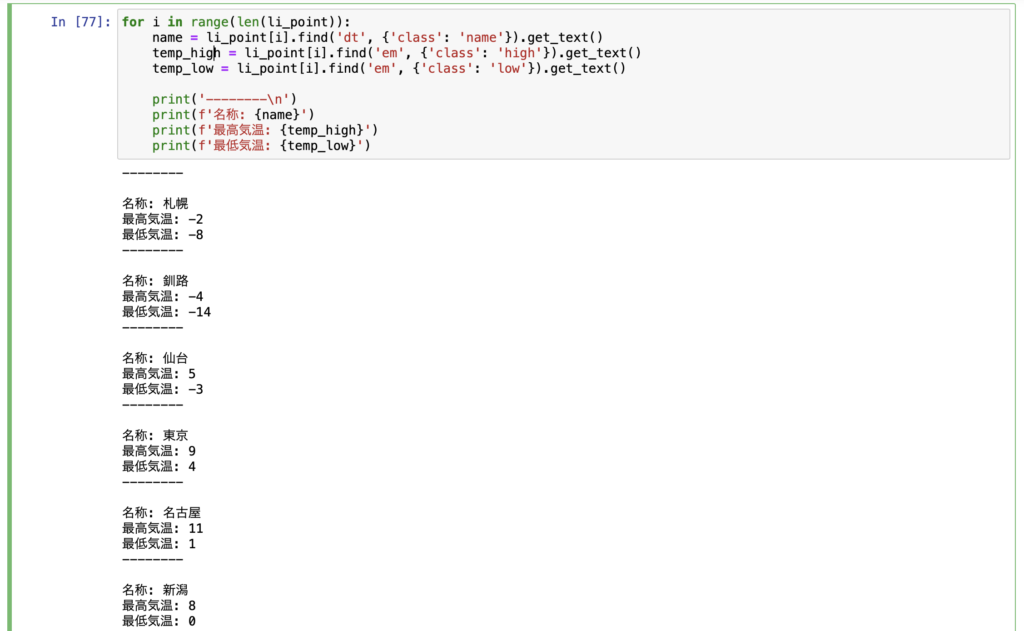
無事欲しい情報のみ抽出できました!
せっかくなので、pandas.DataFrame()を用いて表形式で表示してみます。
import pandas as pd
name_list = []
temp_high_list = []
temp_low_list = []
for i in range(len(li_point)):
# 情報抽出
name = li_point[i].find('dt', {'class': 'name'}).get_text()
temp_high = li_point[i].find('em', {'class': 'high'}).get_text()
temp_low = li_point[i].find('em', {'class': 'low'}).get_text()
# リストに格納
name_list.append(name)
temp_high_list.append(temp_high)
temp_low_list.append(temp_low)
# dfに格納
df = pd.DataFrame({
'name': name_list,
'temp_high': temp_high_list,
'temp_low': temp_low_list
})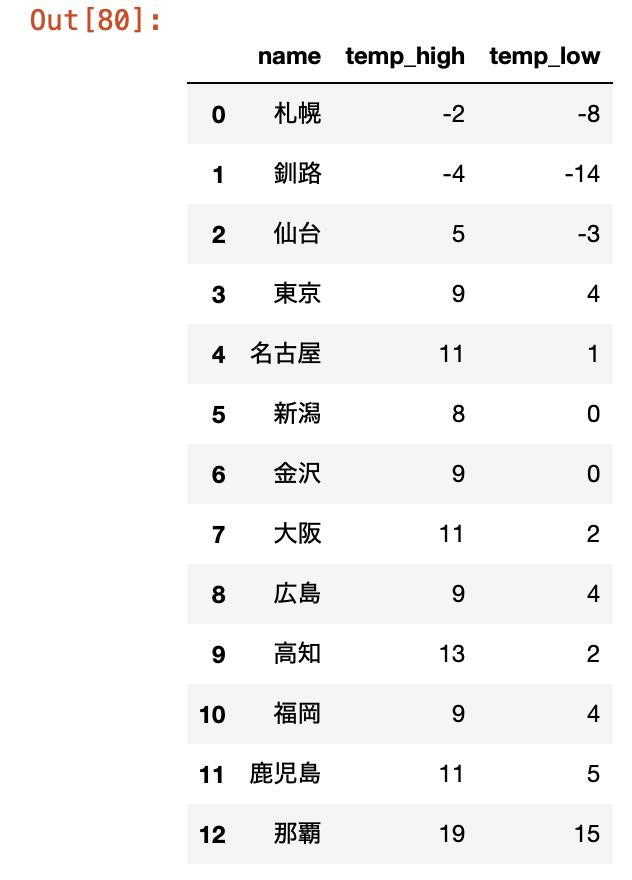
ここまできたらデータを出力するなり加工するなり好き放題弄り倒すことができます。
ここに至るまでのコード全体はこんな感じです。
コード全体
import pandas as pd
import requests
from bs4 import BeautifulSoup
# 該当ページのhtml情報を取得する
url = 'https://weather.yahoo.co.jp/weather/'
html = requests.get(url).content
# 解析する
soup = BeautifulSoup(html, 'html.parser')
# 各地域の情報が格納された<li>タグを抽出
li_point = soup.find('div', {'id': 'map'}).find_all('li', {'class': 'point'})
# 各地域の「名前」「最高気温」「最低気温」を抽出
name_list = []
temp_high_list = []
temp_low_list = []
for i in range(len(li_point)):
# 情報抽出
name = li_point[i].find('dt', {'class': 'name'}).get_text()
temp_high = li_point[i].find('em', {'class': 'high'}).get_text()
temp_low = li_point[i].find('em', {'class': 'low'}).get_text()
# リストに格納
name_list.append(name)
temp_high_list.append(temp_high)
temp_low_list.append(temp_low)
# dfに格納
df = pd.DataFrame({
'name': name_list,
'temp_high': temp_high_list,
'temp_low': temp_low_list
})お疲れ様でした!!!
まとめ
本記事では、スクレイピング初心者の方向けに基礎的な知識などを解説させていただきました。
スクレイピングをすることでサーバーに負荷がかかることをきちんと認識した上で、正しく行なっていただけたらと思います。
また本記事の内容はスクレイピングの知識としてはほんの導入部分のみではありますが、少しでも助けになれば幸いでございます。
もしスクレイピングのご依頼などございましたら是非お声がけください。
ご覧いただきありがとうございました!







コメント