





seleniumを用いたブラウザの自動操作プログラム(スクレイピングなど)を安定的に稼働させるための待機処理についてきちんと理解していますか?
本記事では、そんなseleniumにおける待機処理に関してのテクニックや知識をご紹介していきます!
・待機処理がtime.sleep()しか知らない方
・スクレイピング(自動操作)を安定的に稼働させたい方
※seleniumに関する基本的な知識についてはこちらをご覧ください。

なぜ待機処理は必要?
そもそもなんで待機処理が必要なのかご存知でしょうか??
ページ遷移やフォーム送信など、サーバーからの応答を待つ操作の場合はどうしても時間がかかってしまう場合があります。
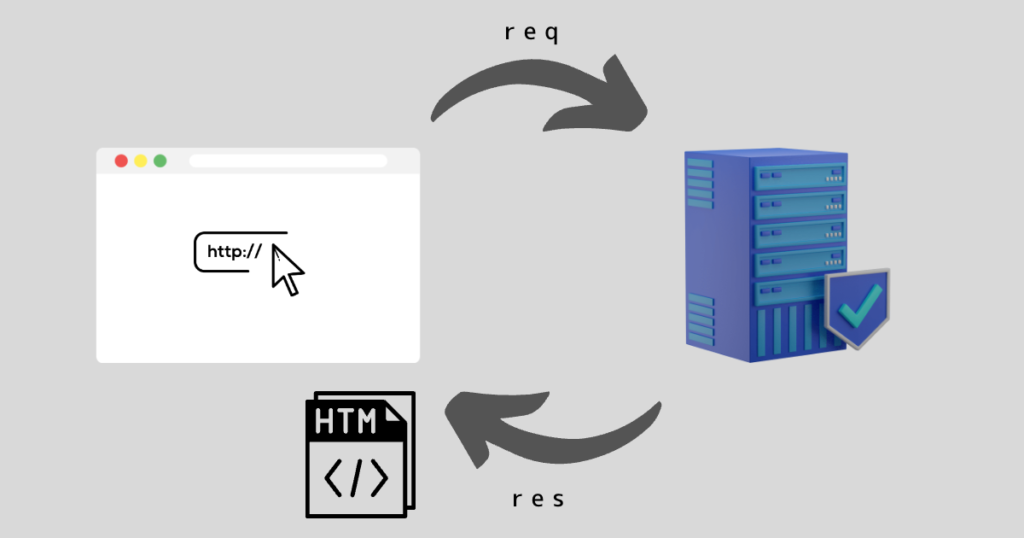
実際は応答が遅れているのにも関わらず、応答が完了している前提でプログラムが進んでしまうとエラーとなってしまいます。
例えばログイン処理の場合を考えてみます。
- ログイン画面に遷移
- フォーム要素を取得
このような流れが考えられますが、ログイン画面にアクセスしたが応答が遅れた場合、フォーム要素がまだブラウザに表示されていないにも関わらず②の取得フェーズに入ってしまうとエラーを起こしてしまいます。
したがって、ちゃんとフォーム要素を取得したのを確認してから次のステップに進めるよう、適切な待機処理が必要になってきます。
待機処理の種類
seleniumを用いた待機処理には大きく分けて次の2種類が存在します。
- 暗黙的な待機
- 明示的な待機
暗黙的な待機とは、find_element()メソッドで要素を取得しようとした時の待機時間の設定のことを指します。
明示的な待機とは、DOM要素がある条件を満たすまで待機させることです。
例えば、「フォーム要素が全て現れるまで待機」「ページ内の全てのDOMが読み込まれるまで待機」などですね。
time.sleep()メソッドもこの明示的な待機に含まれます。
これらの「暗黙的な待機」と「明示的な待機」を組み合わせることで、安定したシステムを構築することができます。
このままでは抽象的なので、具体的な例を交えながら解説していきます!
暗黙的な待機
implicitly_wait()メソッドを用いることで、暗黙的な待機時間を設定できます。
# 暗黙的な定期時間を30秒に設定(デフォルトは0秒)
driver.implicitly_wait(30)簡単です。
これを一度設定しておくだけで、これ以降のfind_element()メソッドを行う際に、要素が見つかるまで指定した時間待機させることができます。
しかし、待機時間内に要素が見つかった場合は次の処理に進んでくれます!
なので上記のコードの場合、最大待機時間は30秒となっておりますが、3秒で要素が見つかった場合の待機時間は「3秒」となります。
無駄な待機時間がないのはいいですね。
chromeを起動した後に、暗黙的な待機時間を設定してあげましょう。
# driver起動
driver = webdriver.Chrome(driver_path)
# 暗黙的な定期時間を30秒に設定(デフォルトは0秒)
driver.implicitly_wait(30)明示的な待機
先ほどの暗黙的な待機のみでは対応しきれない部分については、ここからの明示的な待機で対応してあげます。
WebDriverWait
WebDriverWaitを使用することで、
- 何が
- どんな状態になるまで
を明示的に指定して待機させることができます。
例えば、、、
| 何が | どんな状態 |
| 指定した要素 | 表示される |
| 指定したテキスト | 表示される |
| ページ内のすべての要素 | 読み込まれる |
| 指定した要素 | 現れる |
| Alert | 表示される |
| 指定した要素 | クリックできる状態になる |
などがあります。
具体的に「idが “login-btn”の要素が現れるまで待機」する処理を書いてみます。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# driver起動
driver = webdriver.Chrome(driver_path)
# wait作成(タイムアウトは60秒)
wait = WebDriverWait(driver=driver, timeout=60)
# ページ遷移
driver.get([適当なURL])
# id="login-btn"の要素が現れるまで待機
wait.until(EC.presence_of_element_located((By.ID, 'login-btn')))
# id="login-btn"の要素を取得
login_btn = driver.find_element(By.ID, 'login-btn')10行目のようにまずwaitオブジェクトを作成し、wait.until…と記載(16行目)することで待機処理を行うことができます。
またこの待機処理の結果、19行目の処理を安定して行うことができます。
ここではpresence_of_element_locatedを使用しましたが、他にも様々なメソッドが存在します。
| メソッド | 何が | どんな状態 |
| visibility_of_element_located | 指定した要素 | 表示される |
| text_to_be_present_in_element | 指定したテキスト | 表示される |
| presence_of_all_elements_located | ページ内の全ての要素 | 読み込まれる |
| presence_of_element_located | 指定した要素 | 現れる |
| alert_is_present | Alert | 表示される |
| element_to_be_clickable | 指定した要素 | クリックできる状態になる |
ここでは一部のみ抜粋しておりますが、他にも気になる方はこちらからご確認ください。
これらを使用することで、遅延読み込み(LazyLoad)にも対応することができます。
time.sleep()
ここまでに紹介した待機手段(implicitly_wait()、WebDriverWait)でどーーーーしても対応できなかった場合は、このtime.sleep()メソッドを使用します。
time.sleep()を使用することで、欲しい要素が表示されてようがされてなかろうが、強制的に任意の時間待機させることができます。
from time import sleep
# 強制的に10秒待機
sleep(10)なので余分な待機時間が発生してしまう可能性があるので賢い待機方法とは言えません。
ただし!
サーバーへの負荷の調整のために使用する場合はその限りではありません。
例えば、100ページ分のスクレイピングプログラムがあるとします。
1ページあたりの処理時間が0.5秒だとすると、0.5秒おきにアクセスすることになってしまいます。
なのでもう少しインターバルを意図的に開けたい場合などは、time.sleep()メソッドを使用すると良いでしょう。
# スクレイピングしたいURLのリスト
url_list = [ ...URLのリスト... ]
# 各URLに対する処理
for url in url_list:
# ページ遷移
driver.get(url)
# ...なんかしらの処理...
# 待機(アクセス間隔調整)
sleep(3)まとめ
本記事では、スクレイピングなどのブラウザ自動操作を安定的に稼働させるための必須知識である待機処理についてご紹介させていただきました。
サイトによってはスクロールしないと要素が表示されない、、、なんていう曲者のページもありますが、基本的には本記事でご紹介した方法を活用できるのかと思います。
seleniumを用いてスクレイピングなどをお考えの方は是非本記事をご参考にしてください。
ご覧いただきありがとうございました!






08-300x158.png)
コメント